
Hiện nay có rất nhiều trang web cần phải chứa lượng lớn dữ liệu cực kỳ quan trọng, trong đó phải kể đến thống kê số liệu, cổ phiếu, sản phẩm và thông tin liên hệ của công ty, doanh nghiệp. Để có thể truy cập vào những thông tin này thì người sử dụng sẽ cần đến Web Scraping. Tuy nhiên Web Scraping là gì? Mục đích của Web Scraping như thế nào? Đâu là những Web Scraping độc hại cần né tránh? Tất cả những thắc mắc về Web Scraping này sẽ được giải đáp qua bài viết dưới đây.
Những Điều Cần Biết Về Web Scraping
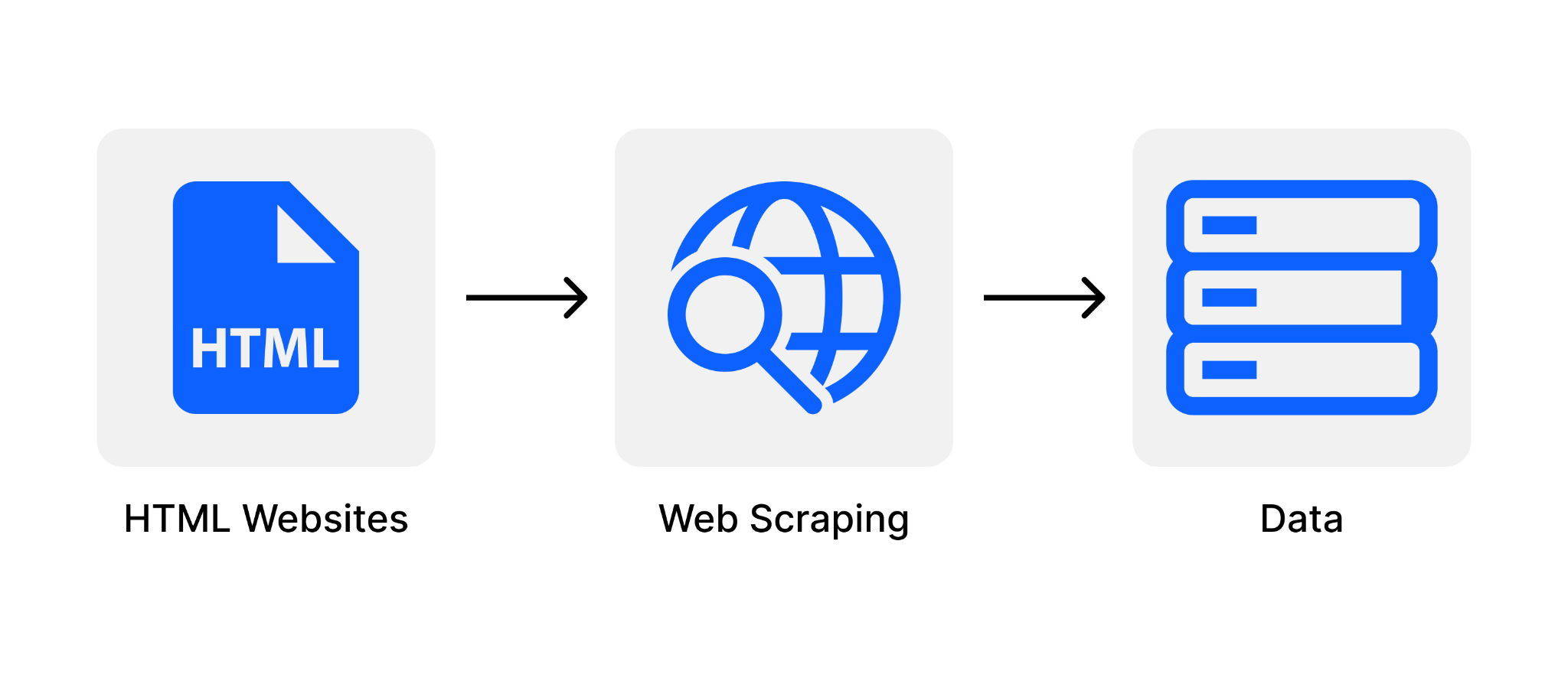
Khái niệm về Web Scraping
Web Scraping hay còn được gọi là Web Harvesting và Web data extraction. Web Scraping chính là quá trình cào dữ liệu đã được sử dụng, mục đích để có thể trích xuất toàn bộ dữ liệu từ các trang website. Các phần mềm Web Scraping sẽ được truy cập vào trang web bằng giao thức HTTP hoặc cũng có thể bằng web browser.
Điều này để nhằm mục đích lấy ra đa dạng các dữ liệu mà họ đang quan tâm đến. Quá trình này cũng được thực hiện thủ công bằng những phương pháp sử dụng phần mềm máy chủ. Tuy nhiên, phần lớn khi nhắc đến Web Scraping sẽ tương đương với quá trình thu thập dữ liệu tự động, đồng thời sẽ được triển khai bằng bot hoặc bằng các web crawler.
Không giống với Screen Scraping đó chính là chỉ sao chép các pixel hiển thị tại màn hình mà Web Scraping lúc này sẽ sở hữu nhiệm vụ chính là trích xuất mã HTML bên dưới. Đi kèm với đó thì dữ liệu của máy sẽ được lưu trữ dưới dạng Database. Sau đó thì scraper sẽ sao chép toàn bộ nội dung của trang web ở những nơi khác.
Ngoài ra, Web Scraping trên web sẽ được sử dụng trên đa dạng các loại hình kinh doanh kỹ thuật số dựa vào quá trình thu thập đa dạng các dữ liệu. Các trường hợp sử dụng hợp pháp điển hình như sau:
-
Các bot của công cụ tìm kiếm có nhiệm vụ thu thập các thông tin cho một trang web, đồng thời là phân tích nội dung của nó và sau đó sẽ có nhiệm vụ xếp hạng nó.
-
Tất cả các trang web so sánh giá triển khai bot mục đích để có thể tự động tìm kiếm giá, đồng thời là mô tả sản phẩm cho đa dạng các seller trên trang web.
-
Đa dạng các công ty nghiên cứu thị trường lúc này sẽ sử dụng scraper với mục đích để có thể lấy được dữ liệu từ các forum và phương tiện truyền thông xã hội.
Mục đích sử dụng của Web Scraping
Hiện tại, chắc chắn bạn sẽ nghĩ ra một số mục đích để có thể sử dụng được Web Scraping. Dưới đây là một số công dụng phổ biến chỉ có tại Web Scraping.
-
Web Scraping có mục đích trích xuất giá cổ phiếu vào API ứng dụng.
-
Trích xuất đa dạng các dữ liệu YellowPages để đáp ứng mục đích tạo ra những nhóm khách hàng tiềm năng.
-
Trích xuất các dữ liệu từ một công cụ định vị cho cửa hàng mục đích để có thể tạo ra danh sách các địa điểm kinh doanh mới.
-
Web Scraping còn trích xuất đa dạng các sản phẩm từ những trang web đó chính là ebay hoặc amazon để có thể phân tích được các đối thủ cạnh tranh.
-
Web Scraping trích xuất dữ liệu cho trang web trước khi di chuyển trang web này.
-
Web Scraping trích xuất chi tiết đa dạng các sản phẩm với mục đích để có thể so sánh khi mua sắm.
-
Trích xuất dữ liệu tài chính cùng mục đích nghiên cứu thị trường hiện nay.
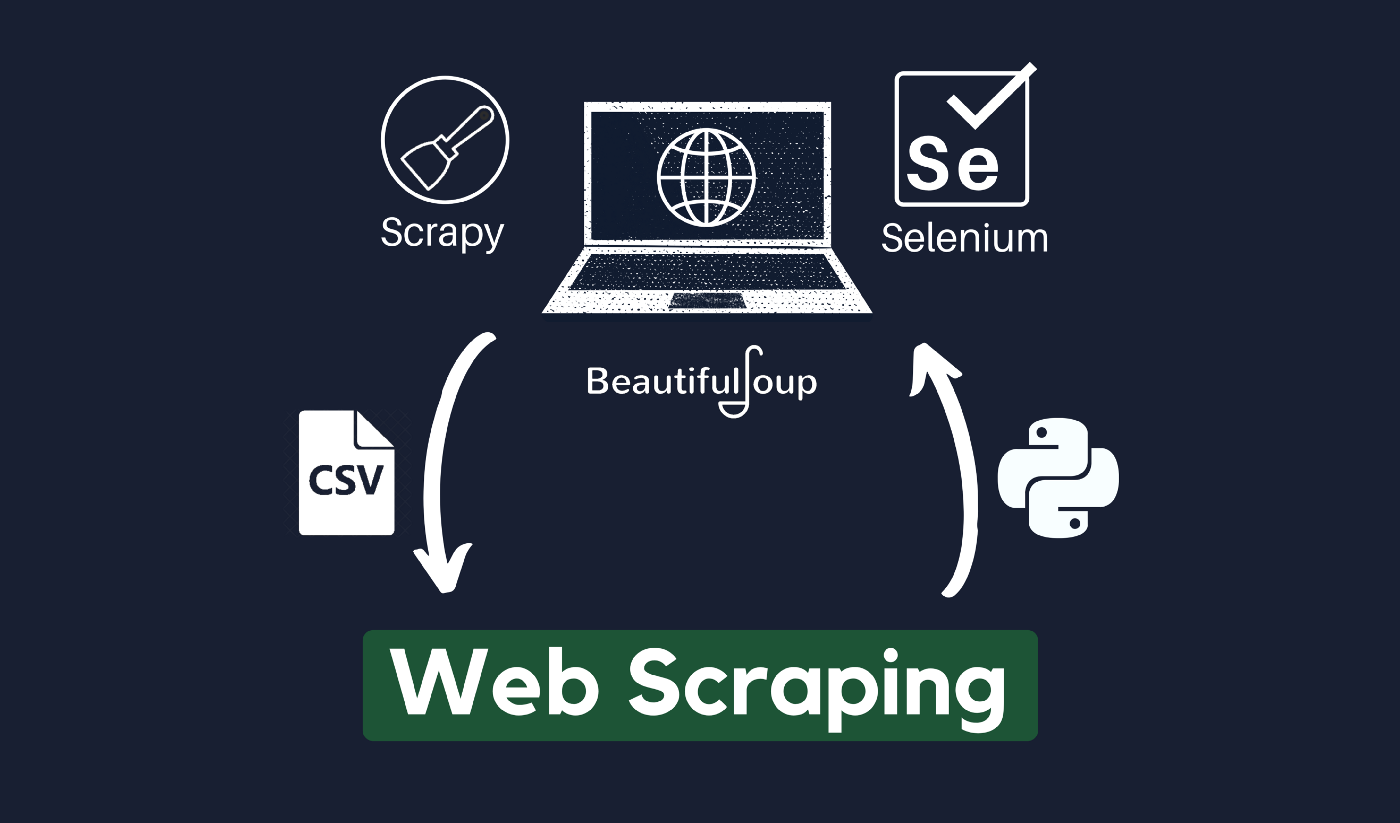
Công Cụ Phổ Biến Của Web Scraping Bạn Đã Biết?
Khi đã nắm rõ được khái niệm của Web Scraping cũng như mục đích sử dụng thì nhiều người dùng vẫn băn khoăn không biết Web Scraping có công cụ phổ biến như thế nào và nó sử dụng nhằm mục đích gì. Web Scraping được biết đến là phần mềm, đây cũng chính là bot đã được lập trình để có thể sàng lọc thông qua database và trích xuất được thông tin. Có rất nhiều các loại bot đã được sử dụng và có khả năng trong việc tùy chỉnh nhằm mục đích:
-
Nhận ra cấu trúc cho mọi trang web HTML.
-
Trích xuất và chuyển đổi gần như toàn bộ nội dung một cách dễ dàng.
-
Lưu trữ cũng như sử dụng dữ liệu đã trải qua quá trình scrape.
-
Trích xuất toàn bộ dữ liệu từ các API.

Lý do bởi tất cả các Web Scraping lúc này đều sở hữu chung một mục đích đó chính là truy cập dữ liệu đối với trang web. Do đó, điều này có thể sẽ rất khó phân biệt giữa bot hợp pháp cùng với bot độc hại. Dưới đây chúng tôi sẽ chia sẻ một số khác biệt giữa hai bot này.
-
Bot hợp pháp: Sẽ được xác định cùng với tổ chức mà chúng muốn scrape. Điển hình có thể kể đến như Google bot sẽ tự nhận dạng được mình trạn Header HTTP. Đồng thời lúc này nó sẽ thuộc về Google. Ngược lại thì toàn bộ các bot độc hại sẽ mạo danh lưu lượng truy cập hợp pháp bằng phương pháp tạo ra tác nhân người sử dụng HTTP giả.
-
Các bot hợp pháp lúc này sẽ được tuân theo file robots.txt. File này sẽ đảm bảo liệt kê đa dạng các trang mà bot sẽ được phép truy cập. Đồng thời những trang mà bot không có quyền quy cập vào. Mặt khác thì những scraper độc hại sẽ có khả năng trong việc thu thập dữ liệu đối với trang web bất kể nhà điều hành trang web nào không có phép đến.

Thực tế thì tài nguyên cần thiết để có thể chạy các Web Scraping bot cực kỳ nhiều, nó nhiều đến mức mà các nhà điều hành bot hợp pháp lúc này sẽ đầu tư cực kỳ nhiều vào các server. Mục đích để có thể xử lý được một lượng dữ liệu đã được trích xuất.
Những hacker lúc này sẽ thường được sử dụng botnet hay còn được gọi là máy đã được phân tán ở đa dạng những nơi khác nhau. Các web này có cùng một malware, đồng thời nó được kiểm soát từ vị trí nhất định nào đó. Các chủ sở hữu botnet sẽ không biết đến sự tham gia của các hacker hiện nay. Ngoài ra thì sức mạnh tổng hợp đối với các hệ thống lúc này sẽ bị nhiễm theo do hacker scraper trên quy mô lớn hơn rất nhiều so với trang web.
Top Web Scraping Độc Hại Mà Bạn Nên Né Tránh?

Web Scraping được cho rằng độc hại chỉ khi dữ liệu này của trang web được trích xuất mà không có sự cho phép đối với chủ sở hữu của tất cả các trang web. Hai trường hợp sử dụng phổ biến nhất đó chính là Price Scraping cùng với đánh cắp nội dung.
Price Scraping
Trong Price Scraping thì cá hacker sẽ thường sử dụng các mạng botnet nhằm mục đích để có thể khỏi chạy cá bot đối với việc kiểm tra database. Từ đó nhằm mục đích để có thể truy cập thông tin về giá cả cũng như có thể cắt giảm đi các đối thủ khác. Đồng thời chính là đảm bảo và thúc đẩy được doanh số bán hàng.
Tất cả các cuộc tấn công sẽ thường xuyên được xảy ra trong đa dạng các ngành mà sản phẩm còn có thể dễ dàng trong việc so sánh. Bên cạnh đó thì giá cả chính là yếu tố đóng vai trò cực kỳ quan trọng đối với việc quyết định mua hàng. Nạn nhân của vấn đề Price Scraping lúc này sẽ bao gồm người bán vé, tất cả các nhà cung cấp thiết bị điện tử online hoặc các công ty du lịch.
Đánh cắp nội dung
Đánh cắp nội dung ở đây sẽ bao gồm việc đánh cắp nội dung sở hữu quy mô lớn từ một số trang web nào đó. Đa dạng các mục tiêu điển hình đó là danh mục sản phẩm online cùng với rất nhiều các trang web dựa trên kỹ thuật nội dung số. Mục đích lúc này có thể thúc đẩy được hoạt động kinh doanh sao cho mạnh mẽ. Đối với đa dạng những doanh nghiệp này thì chỉ cần một cuộc tấn công, đánh cắp nội dung có thể xảy ra vô cùng tàn khốc đối với họ.
Web Scraping Và Bảo Mật Cần Nắm Bắt

Hiện nay, các bot scraper độc hại được gia tăng với tốc độ đáng kể. Điều này đã khiến cho một số phương pháp bảo mật thông thường sẽ không đạt hiệu quả. Tuy nhiên đâu là những cách bảo mật của Web Scraping? Để có thể chống lại tất cả những tiến bộ mà nhà khai thác bot độc hại thực hiện thì lúc này những nhà nghiên cứu cần sử dụng, phân tích lưu lượng được truy cập chi tiết.
Nó đã đảm bảo rằng toàn bộ những lưu lượng truy cập đến với trang web của bạn, cả bot và con người hoàn toàn là hợp pháp. Quá trình này sẽ bao gồm đa dạng các yếu tố như sau:
0 fingerprint
Quá trình lọc lúc này đã bắt đầu bằng với việc kiểm tra chi tiết toàn bộ những header HTTP. Toàn bộ những việc này có khả năng cao trong việc cung cấp đa dạng các manh mối về quá trình khách hàng truy cập người hay bot, để biết được độc hại hay an toàn. Chữ ký của header lúc này đã được so sánh với cơ sở dữ liệu được cập nhật liên tục tổng cộng hơn 10 triệu biến thể khác nhau.
IP Reputation

Tất cả các nhà nghiên cứu đã thu thập được dữ liệu IP Reputation từ toàn bộ những cuộc tấn công chống lại khách hàng. Toàn bộ những lượt truy cập lúc này từ các địa chỉ IP sở hữu tiền sử đã bị sử dụng trong các vụ tấn công lúc này được coi là nghi ngờ, hơn nữa nó cần phải xem xét lại sao cho kỹ lưỡng.
Phân tích hành vi
Tất cả các nhà nghiên cứu lúc này đã thực hiện nhiệm vụ theo dõi toàn bộ các khách truy cập. Đồng thời là tương tác với một trang web khác nhau. Có thể thấy rằng các kiểu hành vi bất thường đều được hiển thị, Điển hình đó là tỷ lệ yêu cầu mạnh mẽ một cách đáng ngờ và đi kèm với đó chính là kiểu duyệt web phi logic. Chắc chắn điều này sẽ giúp phát hiện ra những bot đang truy cập vào website.
Các challenge liên tục

Tất cả các nhà nghiên cứu lúc này đã sử dụng hàng loạt các challegen liên tục với nhau. Trong đó bao gồm cookie support. Đồng thời đó chính là thực thi Javascript mục đích để có thể lọc ra được bot. Phương án cuối cùng đó chính là một Captcha sẽ có khả năng trong việc loại bỏ các bot cố gắng để vượt qua giống như con người.
Hy vọng với bài viết Web Scraping là gì và những vấn đề liên quan đã giúp bạn có thể hiểu rõ ràng khái niệm về Web Scraping. Web Scraping được đánh giá là một trong những công cụ tuyệt vời, mang đến nhiều lợi ích cho người sử dụng trong việc lưu trữ các tài liệu, bộ nhớ quan trọng.