
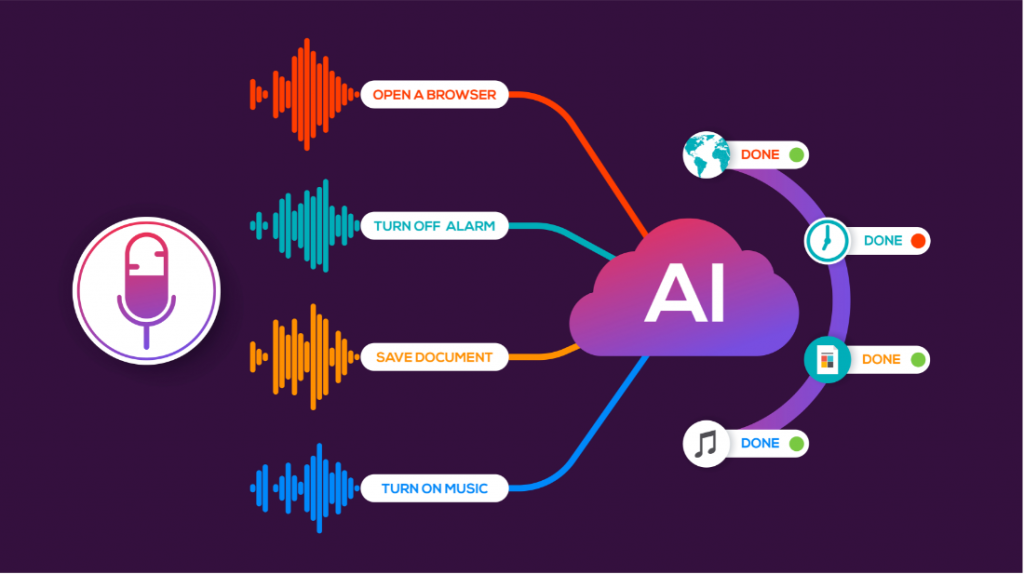
Tính Năng Cơ Bản
Độ chính xác cao
Với việc sử dụng các công nghệ tiên tiến thế giới như mạng nơron sâu kết hợp với các giải pháp cho đặc thù tiếng Việt, dịch vụ nhận dạng tiếng nói của chúng tôi cho kết quả nhận dạng với độ chính xác rất cao
Đầu vào đa dạng
Hệ thống có thể nhận dạng các đầu vào: Giọng đọc có thể được thu âm trực tiếp hoặc thu âm qua điện thoại, qua tổng đài
An toàn, bảo mật cao
Bằng việc tự xây dựng hệ thống nhận dạng và sở hữu các máy chủ, chúng tôi đảm bảo an toàn và bảo mật tuyệt đối cho các dữ liệu của khách hàng
Khái quát về công nghệ nhận dạng tiếng nói
ASR là một nhánh của Học máy (Machine Learning – ML). Về cơ bản, thay vì lập trình các quy tắc để chuyển đổi dữ liệu đầu vào (giọng nói) thành đầu ra (văn bản), thì mô hình Học máy được đào tạo bằng cách đưa các tập dữ liệu lớn vào một thuật toán, chẳng hạn như mạng nơ-ron tích chập (CNN). Trải qua quá trình đào tạo, mô hình ngày càng suy luận tốt hơn, và có khả năng nhận dạng tiếng nói của con người.
Đáng nói, cần phân biệt giữa công nghệ tự động nhận dạng tiếng nói (ASR) và xử lý ngôn ngữ tự nhiên (NLP). ASR liên quan đến việc chuyển đổi dữ liệu giọng nói thành dữ liệu văn bản, trong khi NLP tìm cách “hiểu” ngôn ngữ để thực hiện các tác vụ khác. Hai công nghệ này thường đi kèm với nhau. Ví dụ, một chiếc loa thông minh sử dụng ASR để chuyển đổi lệnh thoại thành một định dạng có thể sử dụng, trong khi NLP xác định nội dung, ý nghĩa của lệnh thoại đó.
Một số công nghệ và thuật ngữ trong ASR
Theo cách truyền thống, hầu hết ASR bắt đầu với một mô hình âm thanh, thể hiện mối quan hệ giữa tín hiệu âm thanh với các đơn vị cơ bản cấu thành nên từ. Mô hình âm thanh này thực hiện chuyển đổi sóng âm thanh thành các bit mà máy tính có thể sử dụng. Sau đó, các mô hình ngôn ngữ và phát âm lấy dữ liệu này, áp dụng ngôn ngữ học tính toán (computational linguistics) và đặt từng âm thanh theo trình tự và ngữ cảnh để tạo thành từ và câu.
Tuy nhiên, các nghiên cứu mới nhất đang bỏ qua cách tiếp cận đa thuật toán này để chuyển sang sử dụng một mạng nơ-ron duy nhất được gọi là mô hình đầu cuối (end-to-end – E2E). Theo nhiều nhà khoa học, mô hình E2E cho phép việc mở rộng sang nhiều ngôn ngữ khác ngoài tiếng Anh trở nên nhanh chóng hơn, đồng thời dễ dàng đào tạo các mô hình mới và tiết kiệm thời gian giải mã (decoding).
Một kỹ thuật quan trọng khác là tách kênh giọng nói (speaker diarization), cho phép mô hình nhận dạng giọng nói xác định người nói và thời điểm nói. Điều này không chỉ quan trọng đối với các trường hợp ghi chép báo cáo cuộc họp, hội nghị với nhiều diễn giả, mà còn góp phần hướng tới cá nhân hóa trải nghiệm người dùng.
Để đánh giá mức độ chính xác của mô hình ASR, các nhà nghiên cứu hay sử dụng tỷ lệ lỗi từ (Word Error Rate – WER) theo công thức:
Tỷ lệ lỗi từ = (số lần chèn + xóa + sai) / số từ trong bảng điểm tham chiếu
Như vậy, đơn giản hơn, có thể hiểu WER cung cấp tỷ lệ phần trăm các từ mà ASR đã nhầm lẫn.
Phần mềm nhận dạng tiếng nói là gì?

Lợi ích của phần mềm nhận dạng giọng nói
Tiết kiệm tối đa thời gian
Đảm bảo độ chính xác cao

Định dạng nhanh chóng
Tương lai của ASR
Chúng ta đang bước vào kỷ nguyên của Internet vạn vật kết nối (Internet of Things – IoT). IoT bao gồm tất cả các thiết bị “thông minh” tồn tại xung quanh ta, từ thiết bị gia đình như điều hòa, loa đến các thiết bị công nghiệp nhằm tối ưu hóa quy trình sản xuất và thúc đẩy quá trình tự động hóa. Tương lai, giọng nói sẽ nhanh chóng trở chiếm ưu thế và trở thành cách thức ưu việt nhất để người dùng tương tác với IoT. Chỉ cần nói “bật đèn” hoặc “tăng nhiệt độ”, chúng ta có thể kiểm soát điều kiện môi trường trong thời gian thực, mà không cần phải nhìn vào màn hình hay nhấn các nút vật lý.
Mô hình AI giúp chuyển đổi giọng nói thành văn bản với tỷ lệ WER nhỏ hơn 6%. Đặc biệt, lần đầu tiên tại Việt Nam, trợ lý ảo có thể hiểu ngôn ngữ đặc thù từng vùng miền, giúp đem lại trải nghiệm sử dụng đầy thuận tiện, dễ dàng cho người sử dụng.