

Công nghệ cho phép tự động chuyển đổi văn bản thành tiếng nói Tiếng Việt giúp doanh nghiệp tự động hóa quá trình cung cấp sản phẩm dịch vụ, nâng cao hiệu quả hoạt động sản xuất kinh doanh. Giọng đọc nhân tạo Viettel AI có ngữ điệu tự nhiên, đa dạng vùng miền, dễ dàng tích hợp với mọi hệ thống
Tính Năng Cơ Bản
Giọng nói tự nhiên
Với việc sử dụng các công nghệ tiên tiến thế giới về xử lý ngôn ngữ tự nhiên, xử lý tiếng nói, học sâu, hệ thống tổng hợp cho giọng đọc tự nhiên, ngắt nghỉ tự động và kết hợp biểu cảm chính xác
Giọng đọc đa dạng
Hiện tại chúng tôi cung cấp giọng đọc báo, đọc truyện với cả 3 vùng miền: Bắc (3 giọng nữ, 2 giọng nam), Trung (1 giọng nữ, 1 giọng nam), Nam (3 giọng nữ, 1 giọng nam)
Đáp ứng nhanh chóng
Sử dụng số lượng lớn các máy chủ mạnh với công nghệ tính toán song song cho phép đáp ứng nhanh chóng mọi yêu cầu của khách hàng, ngay cả trong trường hợp tải tăng đột biến
Ứng Dụng Thực Tế
Hệ thống thông báo, IoT, Robotics
Hỗ trợ các hệ thống thông báo, phát thanh, hướng dẫn tại sân bay, đài truyền hình, bệnh viện hoặc Smart Home…
Thuyết minh / Tổng đài tự động
Tiết kiệm chi phí, thời gian, tăng năng suất và chất lượng cho các dịch vụ thuyết minh, bán hàng hoặc CSKH qua điện thoại
Sách / Báo nói
Cho phép người dùng lắng nghe nội dung trực tiếp trên các trang sách báo online khi đi đường, lái xe, đi tàu. Đặc biệt hỗ trợ người khiếm thị
Tổng hợp tiếng nói và ứng dụng
Tổng hợp tiếng nói (TTS: Text to Speech) về bản chất là quá trình tạo tín hiệu tiếng nói từ văn bản. Một hệ thống tổng hợp tiếng nói có thể được ứng dụng trong rất nhiều bài toán khác nhau có thể lấy ví dụ như báo nói Dân trí, một sản phẩm mà tôi đã tham gia phát triển, ngoài ra các ứng dụng của trí tuệ nhân tạo như trợ lý ảo, tổng đài tự động,… đều cần mô đun đầu ra là hệ thống tổng hợp tiếng nói. Hiện nay có rất nhiều sản phẩm thuộc các chủng loại khác nhau được ứng dụng vào các mục đích khác nhau, nhưng lớn mạnh nhất phải kể đến các sản phẩm được phân phối trên Google Cloud, Amazon Web Services, Microsoft Azure. Những cloud này cho phép các bạn tích hợp hệ thống TTS của họ vào các sản phẩm cá nhân của mình. Ở Việt Nam và dành cho tiếng Việt cũng có các sản phẩm nổi bật như sản phẩm của Viettel, FPT hay Vbee.
Lịch sử phát triển
Tổng hợp tiếng nói về bản chất là quá trình tạo tín hiệu tiếng nói từ văn bản. Trong nhiều năm trở lại đây, người ta cố gắng tạo ra một hệ thống tổng hợp sao cho có độ tự nhiên cao nhất (Naturaless) và đọc dễ hiểu nhất (Intelligibility).
Một trong những nghiên cứu đầu tiên mà ta phải nói đến chính là mô hình mô phỏng hệ thống cấu âm của con người do nhà khoa học người đan mạch Christian Kratzentein phát triển, hệ thống đơn giản này có thể phát ra được âm thanh của một số nguyên âm dài như (/a/, /e/, /i/, /o/, và /u/), ngoài ra nhiều phiên bản cải tiến cũng được phát triển trong thời gian sau đó. Tuy nhiên trải qua một quá trình dài phát triển, ngay cả tới tận thế kỷ 19 các nghiên cứu tổng hợp tiếng nói vẫn còn ở mức đơn giản.
Tới đầu thế kỷ 20, khi mà có sự lớn mạnh của các hệ thống điện tử, thì các hệ thống tổng hợp có chất lượng mới được phát triển. Năm 1937, The Bell Telephone Laboratory đã giới thiệu VODER (Voice Operating Demonstator), đây có thể nói là hệ thống điện tử đầu tiên của con người có thể tổng hợp tiếng nói bằng cách phân tích các đặc trưng âm học.
Ngoài các hệ thống tổng hợp tiếng anh thì tới năm 1975 MUSA được giới thiệu với khả năng tổng hợp tiếng ấn độ. Nhưng vẫn chưa có gì gọi là tổng hợp nhiều ngôn ngữ cả, phải tới khi Bell labs công bố nghiên cứu của họ về việc tổng hợp đa ngôn ngữ dựa trên các hướng tiếp cận “Xử lý ngôn ngữ tự nhiên” năm 1997 thì lĩnh vực này mới bắt đầu được khai thác. Nhìn chung, đến thời điểm này chất lượng của các hệ thống tổng hợp vẫn còn rất tệ, phải đến đầu những năm 2000 chất lượng và độ tự nhiên mới có sự nhảy bậc khi áp dụng tổng hợp thống kê dựa trên các mô hình Markov ẩn. Gần đây những nghiên cứu về mạng nơ ron học sâu được dẫn đầu bởi Google đã cho thấy những bước tiến nổi bật khi áp dụng vào tổng hợp tiếng nói, chất lượng đã đạt đến độ rất cao và khó có thể phân biệt là người hay máy nói.
Các phương pháp tổng hợp tiếng nói
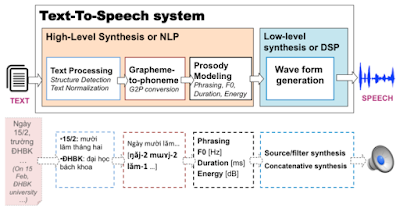 |
| Hình 1: Kiến trúc chung của các hệ thống tổng hợp tiếng nói theo hướng cổ điển. |
Tổng hợp mô phỏng hệ thống phát âm
Tổng hợp tần số Formant
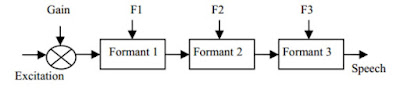 |
| Hình 2: Hệ thống tổng hợp Formant nối tiếp. |
Tổng hợp ghép nối
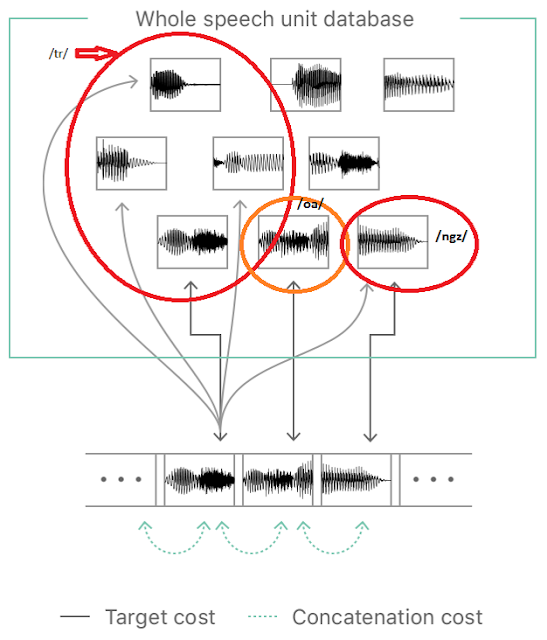 |
| Hình 3: Quá trình tổng hợp ghép nối |
Có ba kiểu tổng hợp ghép nối chính:
- Tổng hợp chọn đơn vị (Unit selection)
- Tổng hợp âm kép (Diphone)
- Tổng hợp chuyên biệt (Domain-specific)
Tổng hợp chọn đơn vị dùng một cơ sở dữ liệu lớn các giọng nói ghi âm. Trong đó, mỗi câu được tách thành các đơn vị khác nhau như: các tiếng đơn lẻ, âm tiết, từ, nhóm từ hoặc câu văn. Một bảng tra các đơn vị được lập ra dựa trên các phần đã táchvà các thông số âm học như tần số cơ bản, thời lượng, vị trí của âm tiết và các tiếng gần nó. Khi chạy các câu nói được tạo ra bằng cách xác định chuỗi đơn vị phù hợp nhất từ cơ sở dữ liệu. Quá trình này được gọi là chọn đơn vị và thường cần dùng đến cây quyết định được thực hiện. Thực tế, các hệ thống chọn đơn vị có thể tạo ra được giọng nói rất giống với người thật, tuy nhiên để đạt độ tự nhiên cao thường cần một cơ sở dữ liệu lớn chứa các đơn vị để lựa chọn.
Tổng hợp âm kép là dùng một cơ sở dữ liệu chứa tất cả các âm kép trong ngôn ngữ đang xét. Số lượng âm kép phụ thuộc vào đặc tính ghép âm học của ngôn ngữ. Trong tổng hợp âm kép chỉ có một mẫu của âm kép được chứa trong cơ sở dữ liệu, khi chạy thì lời văn được chồng lên các đơn vị này bằng kỹ thuật xử lý tín hiệu số nhờ mã tuyên đoán tuyến tính hay PSOLA. Chất lượng âm thanh tổng hợp theo cách này thường không cao bằng phương pháp chọn đơn vị nhưng tự nhiên hơn cộng hưởng tần số và ưu điểm của nó là có kích thước dữ liệu nhỏ.
Tổng hợp chuyên biệt (Domain-specific) là phương pháp ghép nối từ các đoạn văn bản đã được ghi âm để tạo ra lời nói. Phương pháp này thường được dùng cho các ứng dụng có văn bản chuyên biệt, cho một chuyên nghành, sử dụng từ vựng hạn chế như các thông báo chuyến bay hay dự báo thời tiết. Công nghệ này rất đơn giản và đã được thương mại hóa từ lâu. Mức độ tự nhiên của hệ thống này có thể rất cao vì số lượng các câu nói không nhiều và khớp với lời văn, âm điệu của giọng nói ghi âm. Tuy nhiên hệ thống kiểu này bị hạn chế bởi cơ sở dữ liệu chuyên biệt không áp dụng được cho miền dữ liệu mở.
Tổng hợp dùng tham số thống kê
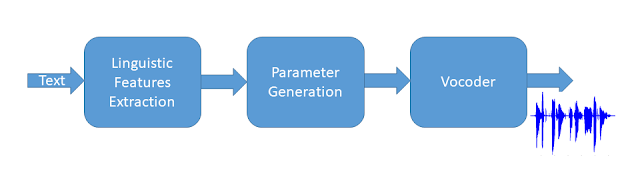 |
| Hình 4: Tổng hợp tham số thống kê
Hình 4 mô tả kiến trúc phổ thông của một hệ thống tổng hợp tham số thống kê. Trong đó văn bản đầu vào sẽ được trích chọn thành các đặc trưng ngôn ngữ học bởi bộ Trích chọn đặc trưng ngôn ngữ (Linguistic Features Extraction). Sau đó các đặc trưng ngôn ngữ này đi qua bộ Parameter Generation và bộ này sẽ ước lượng được đặc trưng âm học ở đầu ra. Cuối cùng Vocoder tổng hợp tín hiệu tiếng nói từ những đặc trưng âm học này,Ngoài việc sử dụng riêng rẽ các phương pháp tổng hợp, thì trên thế giới cũng có những nghiên cứu về tổng hợp lai ghép ví dụ như lai ghép giữa tổng hợp thống kê và tổng hợp ghép nối để tận dụng những hưu điểm của hai phương pháp này.
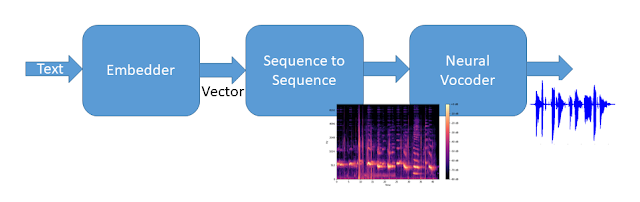
Tổng hợp End to EndTổng hợp End to end là phương pháp mới được phát triển trong những năm gần đây. Mục tiêu của phương pháp này là tạo ra hệ thống tổng hợp có chất lượng cao nhất mà không cần dùng đến các kiến thức chuyên gia dựa trên các mạng nơ ron học sâu. Một kiến trúc nổi bật của phương pháp này có thể kể đến Tacotron2 của Google hay FastSpeech của Microsoft. Kiến trúc chung hay được sử dụng của một hệ thống End to End gồm có hai phần chính là: Phần tạo Mel spectrogram từ chuỗi ký tự đầu vào và phần chuyển hóa Mel spectrogram thành tín hiệu tiếng nói. Hình 5 mô tả kiến trúc một hệ thống tổng hợp End to End, trong đó phần tạo Mel spectrogram gồm hai mô đun là Embedder để chuyển hóa chuỗi ký tự thành chuỗi các véc tơ biểu diễn, sau đó mô đun Sequence to Sequence sẽ ước lượng Mel spectrogram từ chuỗi véc tơ này. Cuối cùng từ Mel spectrogram được chuyển hóa thành tín hiệu tiếng nói nhờ Neural Vocoder.
 |